When Lars Adrian Giske and I arranged this interview, we were each in our respective newsrooms, but alone in quiet rooms. Our colleagues ensured that we could conduct the interview without much noise, which left a strong impression on me. This small gesture highlighted the importance of effective collaboration, which is always crucial, especially when introducing changes and innovations.

Lars Adrian Giske
“The key was finding the right place to apply AI. Some asked why we didn’t automate the writing of the story since we have the documentation and summary. We wanted to ensure humans were in the loop, automating the time-consuming research work and freeing up journalists to do what they do best—call sources and talk to people, where the good stories are. “
“The key was finding the right place to apply AI. Some asked why we didn’t automate the writing of the story since we have the documentation and summary. We wanted to ensure humans were in the loop, automating the time-consuming research work and freeing up journalists to do what they do best—call sources and talk to people, where the good stories are. “
I immediately thought about how crucial support, trust, and strong team cooperation are when implementing new technologies, just as Lars, the Head of AI at the local newspaper iTromsø, did with his colleagues. We discussed the development of the Djinn project, its remarkable success, and the impressive results, including a 33% increase in readership for stories published using it within the first month.
Q. Internally at iTromsø and Polaris Media, you led the Djinn project, where iTromsø, IBM, and their partner Visito built a groundbreaking AI solution for sourcing possible news stories from large amounts of public data. You are also the Product Owner for Djinn, which has now been rolled out to 35 papers across Norway, covering over 130 municipalities. Could you tell us more about this project and the impact it has had?
A. We really started focusing on AI about three years ago. At that time, I was a web editor but also worked as an investigative reporter and researcher, helping my colleagues. We began by integrating basic machine learning into our investigative work, such as prediction models, to uncover stories that hadn’t been told before and find new knowledge in large data sets.
We used data from various sources, combining it to reveal new insights. For instance, we won the Scoop Award, one of Norway’s most prestigious journalism awards, for a project called “Our City/Byen vår”. We combined a lot of open public data about Tromsø, the town I live in, and highlighted social inequalities in a way that hadn’t been done before. This project pinpointed areas where people were unaware of inequalities, leading to the municipality receiving substantial government funding to address these issues.
This marked the beginning of our work with machine learning. From there, it snowballed—we started exploring how to use large language models and more complex systems in our reporting. We identified key points in our workflow where AI could assist us, focusing on routine tasks that could be automated to strengthen our journalists’ work without replacing anyone. We wanted to make our journalists better, enabling them to tell better stories.
One key area we explored was zoning, planning, and development documents from municipalities. Property is very important in Norway, as people invest nearly 90% of their income in their properties. Decisions by the government or local authorities regarding property plans can significantly impact many people, both positively and negatively. This area involves a lot of money and power, with strong development firms influencing politics and government decisions.
All these documents are publicly available in Norway, as municipalities must record all incoming and outgoing correspondence regarding zoning plans. We realized we had access to good data and decided to build a system to analyze it. Instead of manually sifting through thousands of documents, we developed a system that could quickly identify relevant information and patterns. This initiative aimed to support our journalistic mission by providing valuable insights into important public documents.
Q. Could you show us how it works?
A. I’ll show you the municipal web portal in Norway and Tromsø. These are all the incoming and outgoing correspondences. It’s really hard to filter through this every day, and we have to, because we’re in competition with a larger newspaper. We’re the smaller one, but as the city paper, we should be the best at telling our readers how and why Tromsø is changing.
Screenshot of Lars Adrian Giske showcasing the municipal web portal in Tromsø.
All we have to go on is metadata, and we have to download and read every single document, which is incredibly time-consuming. So, we built a system that continuously downloads all new documents, summarizes them, and assigns a news value based on models we’ve trained ourselves. These classifier models are very precise.
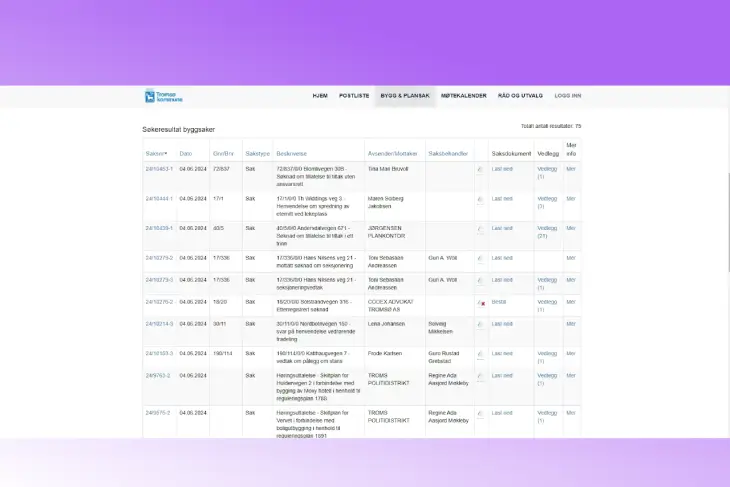
Screenshot of Lars Adrian Giske showing the incoming and outgoing correspondences on the municipal web portal in Tromsø
This tool has replaced the old, inefficient method with a very powerful system that our journalists use. It rates the documents and gives them a news value based on feedback from our journalists. As you can see in the screenshots, it asks if a story is newsworthy, and we retrain the models continuously to improve their precision.
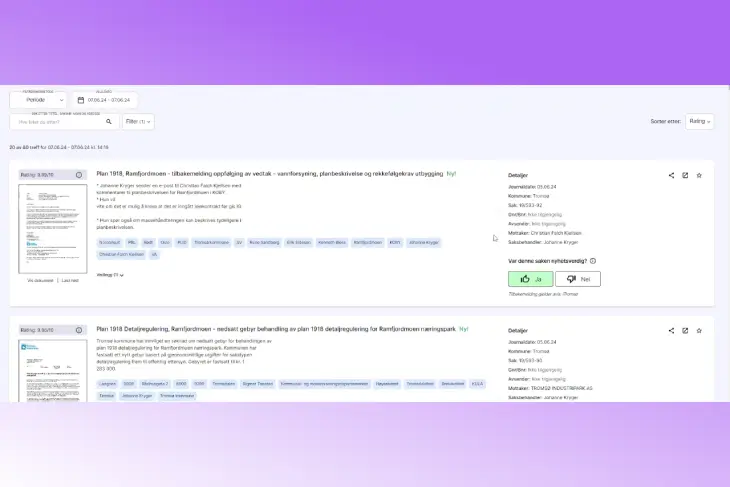
Screenshot of Lars Adrian Giske showcasing the DJINN interface.
The system extracts relevant entities, lets journalists open the document to view the full text, and summarizes it using advanced models. This has made going through these archives incredibly easy. What used to take me an hour and a half now takes just 10 minutes, and we pick up stories we wouldn’t have noticed otherwise. It’s been a huge success.

Screenshot of Lars Adrian Giske demonstrating DJINN’s document analysis feature, allowing users to open and review full-text documents efficiently.
The system extracts relevant entities, lets journalists open the document to view the full text, and summarizes it using advanced models. This has made going through these archives incredibly easy. What used to take me an hour and a half now takes just 10 minutes, and we pick up stories we wouldn’t have noticed otherwise. It’s been a huge success.
Q. Your story is truly inspiring, especially for smaller newsrooms. As you mentioned, you’re a smaller outlet, and there’s often a perception that only the largest and wealthiest newsrooms can utilize such advanced technology. However, your experience proves otherwise. What were the main challenges you faced during this process?
A. The main challenge is, we didn’t really encounter any huge difficulties. It was surprisingly straightforward building the prototype, at least. We did that from April to June last year, together with IBM. We put it into production in June, testing the prototype in our workflow, and got three cover stories in the first week. We realized this had real value—it worked.
We took it to our owner, Polaris Media, and showed them what we made, suggesting that other newspapers in the group try it out. They decided to invest in it, scaling it up to five of the largest newspapers in the company during the fall, and then to 33 more by February this year. Now, anyone with access to the data has access to the platform.
That’s where the challenges come in. There are many different municipalities and data sources using various systems. Some municipalities in Norway, unfortunately, do not publish these documents in full text—60% do, but 40% don’t. We’re still working on this, as it involves resources and the technical solutions municipalities use.
However, we found that four municipalities that didn’t have open sources decided to open their archives for us, making their full-text documentation publicly available for the first time. This project has been well-received, not just by our team but also by stakeholders. They see the value in involving people democratically in how municipalities are changing, which was a positive outcome. It was challenging and a lot of work to normalize the data, but ultimately very rewarding.
Q. We’ve touched on this briefly, but can you elaborate on the impact AI has had on your team’s efficiency and productivity? What changes have you noticed in this area?
A. It’s a multifaceted question because AI encompasses much more than just one project. This specific project has significantly increased our efficiency—about an 80% improvement in the research phase alone. Tasks that used to take over an hour now take just 10 minutes.
Beyond this project, AI has had a broader impact on our workflow. With the Enterprise edition of ChatGPT, more team members are using large language models to structure and analyze data. Tasks that used to take weeks now take only a few minutes. Working with large data sets and combining different data sources has become much faster.
Although it’s challenging to quantify all the benefits precisely, the impact is evident. The way people work has changed dramatically. For instance, tasks that were time-consuming and labor-intensive are now completed quickly and efficiently. The overall productivity boost is significant, and the difference is noticeable compared to just six months ago.
” We identified key points in our workflow where AI could assist us, focusing on routine tasks that could be automated to strengthen our journalists’ work without replacing anyone.”
“It’s crucial for newsrooms to be very discerning about how we use this technology and what we choose not to use at all. We need to maintain the core values of journalism, ensuring that AI serves to enhance, not replace, the essential human elements of our work.”
Q. Partnerships and collaborations seem to be crucial for implementing technological innovations. Can you share examples of successful collaborations that have helped you enhance your work with AI?
A. Yes, definitely. The DJINN project that I’ve been talking about so far is an example of this. It’s a collaboration with IBM, first and foremost. We invested time, they invested time, and together we found a solution that works. We then collaborated with an IBM partner named Visito, based in Bergen, to scale it up and flesh out the solution.
It’s been a co-creation process where we worked with external developers, getting them to understand our needs and challenges in our daily work, and driving that into a development process using design thinking. This approach has been hugely successful, mainly because we involved journalists from day one. We had domain experts in the room at the first workshop, telling us and the developers what their challenges are, and then presenting them with our solutions as we went iteratively.
I was worried when we started to roll out DJINN to other newsrooms, especially smaller ones with just three journalists, often not very technologically savvy. But the reception has been fantastic—they love it. This success is due to good collaboration.
We’re also involved in other projects. For example, we’re working with the University of Bergen on a similar project for political documents and meeting records from municipalities and other government organizations. This has also come about through good collaboration. We’re part of an AI Hub in Bergen, where we have ongoing dialogues with several universities in Norway and collaborate on research projects.
These partnerships give us a network and resources that many small newspapers might not have, and I think this has been key to our success. It’s all about strategic partnerships.

Lars Adrian Giske and data editor Rune Ytreberg during a conference presenting AI work.
Q. Your story is incredibly motivating, especially when it comes to making final decisions on whether, or how, to use new technologies. Speaking of this field, ethical dilemmas are always a concern. What challenges do you most often encounter when using AI?
A. It’s always a balancing act when implementing AI systems. Are you replacing humans? From a journalistic standpoint, are you breaching journalistic ethics? It’s crucial to have guardrails in place to ensure we don’t do something we shouldn’t or publish something inappropriate.
For all AI development, especially within our field, the challenge is whether the systems are enhancing our work without compromising ethics. Some people aim to replace journalists to cut costs, but we don’t want to go down that road. We aim to use AI to empower our journalists and, in turn, our readers by providing new ways to uncover knowledge that were previously inaccessible.
We’re not just talking about large language models but also predictive regression and machine learning, which help us understand how certain factors impact outcomes, offering a more comprehensive picture. This is particularly important in an age of information overload, where it’s challenging to get a proper overview. The more comprehensive an overview we can provide to our journalists, the better informed our readers will be.
We ensure that we always have a human in the loop. We don’t automate the publishing process; instead, we automate the research process. This approach itself poses ethical challenges, such as verifying the accuracy of the information and not being too quick to trust the systems. Since implementing DJINN, we’ve emphasized that while AI can free up time, it must be fact-checked like any other source to ensure accuracy.
Additionally, we had to do extensive work checking the legality and ethics of our actions, particularly regarding data storage. Even though we use open documentation, these public documents contain personal information like names, titles, and addresses. Once this data is stored and combined, it can quickly become sensitive. We went through several rounds with our lawyers before starting this project, and I would advise anyone considering a similar endeavor to begin with legal and compliance checks to avoid potential issues later on.
Q. Is there something that particularly concerns you when it comes to journalism, the future, and AI?
A. We’re talking about changes that almost seem like science fiction, but what’s happening right now is equally important. I’m noticing that both myself and my colleagues are increasingly relying on AI systems like Perplexity for searches and ChatGPT. It’s convenient to have these systems do the thinking for you.
This trend is a bit concerning because in 10 years, when new journalists come straight out of school, their reliance on AI will likely be even greater. Will they have the same opportunities for hands-on training and learning experiences that we did? Developing good judgment and ethical decision-making takes time and practice—it’s not something you can learn entirely in school.
Journalism is a craft, and understanding why you include one quote over another or how you write a story involves a lot of critical thinking and ethical considerations. This is especially true for complex, conflict-related stories. If we lose this depth of thinking, the value of journalism could be compromised.
It’s crucial for newsrooms to be very discerning about how we use this technology and what we choose not to use at all. We need to maintain the core values of journalism, ensuring that AI serves to enhance, not replace, the essential human elements of our work.
Right now, we rely on having a human in the loop, which is fundamental to how we develop AI systems at iTromsø and Polaris. But what if the human in the loop is no longer capable of making the right choices? That’s something that worries me a bit. However, it’s not all catastrophic. I might have made it sound really scary, but I do think that the opportunities this technology presents far outweigh the negatives, as long as it’s handled responsibly.

Photo from the first Djinn workshop, where participants meticulously detailed their vision for the project.
Q. I have one more question regarding the implementation of AI. There are challenges, especially for small-budget or small-team companies. Conversely, we have large companies that are dissatisfied with the impact of their AI initiatives. So, what is your message for both groups? What advice would you give to those starting out or contemplating AI integration, and what lessons can be learned from missteps already taken?
A. In today’s interconnected world, it’s essential to view our solutions as part of broader ecosystems. Startups can benefit from focusing on specific niches and solving problems effectively with AI, gradually expanding their customer base. They might not have the resources for extensive model training, so off-the-shelf or fine-tuned open-source models can be a practical approach.
Large companies often face challenges with experimentation and tend to overly focus on ROI. It’s crucial to encourage rapid experimentation within teams, providing the space and budget to explore without immediate ROI pressure. This shift in mindset empowers teams to learn and maximize impact rather than solely focusing on ROI.
Additionally, large companies should reconsider the dynamics of their R&D teams. Instead of operating in isolation, R&D teams should be integrated with product teams. Product teams have firsthand experience with the problems and can provide valuable insights for experimentation and innovation. By fostering an environment that encourages experimentation and continuous learning, both small and large companies can effectively navigate the challenges of AI integration.
For those starting out, my advice is to embrace the ecosystem mindset and focus on solving specific problems. Explore open-source models and tools to get started without requiring extensive resources. For those who have already taken missteps, reflect on the lessons learned and create space for experimentation. Learn from both your successes and failures, and continuously seek to improve your AI initiatives.
Lastly, remember that AI is an ever-evolving field. Stay informed about the latest advancements, and don’t be afraid to adapt and experiment. By staying agile and open to new ideas, you’ll be well-equipped to navigate the challenges and opportunities that AI presents.
Q. I completely agree with you. It’s crucial for all of us to be aware of these issues. Could you share with us your future plans or ongoing projects?
A. We have many projects underway. One major focus is on transcription, sourcing data from places where we don’t have textual data currently, such as public meetings and political committees. This will provide us with a lot of useful data that we can combine with other data to do some pretty cool stuff, like fact-checking political statements much quicker and more thoroughly.
We’re also working with the University of Bergen and the Center for Investigative Journalism on a project we call the Democracy Base. We’re aiming to collect all political documentation in Norway and build features like semantic search, graph network analysis, and more. This will help us uncover new knowledge and keep our readers well-informed. It’s an exciting step beyond what we’ve done with DJINN.
Q. That’s incredible. We’ve mentioned the results and plans, but I’d like to also touch on your motivation for doing all of this. With a background in philosophy and a keen interest in the intersections of science and technology, you have spent over ten years as a journalist and editor, becoming well-versed in investigative and data-driven journalism, with a side of AI development sprinkled on top. What inspired you to explore this innovative field?
A. I’ve always been interested in sci-fi and science. I did my master’s in philosophy, with a focus on the philosophy of mind and the philosophy of language. This naturally led to an interest in artificial intelligence—understanding how these systems work and the progression from basic machine learning algorithms to the possibility of general artificial intelligence. These topics have fascinated me for about 20 years now. The advancements in AI since 2019 have been particularly exciting. The paper “Attention Is All You Need” by Google DeepMind, which introduced the transformer model, marked a major shift in AI research and machine learning. After this paper, we saw more useful language models, and with OpenAI’s launch of ChatGPT in 2022, it was revolutionary. It could do things no other algorithm or architecture had done before. That’s when I realized AI was advancing much faster than I had anticipated, prompting me to adapt and start incorporating these advancements into my work.
Q. Do you have any final messages or advice for our readers who are considering trying out AI tools or already using them?
A. Definitely. I think everyone who has access to AI systems like ChatGPT should play around with them and learn how they work. Try to understand the technology behind them to avoid making mistakes. Start using them in your work because the impact can be huge, but always be careful and mindful of how you implement these tools.
About The Author

Branislava Lovre
Branislava Lovre works with media organizations, CSOs, and institutions to implement ethical AI in practice, delivering hands-on training, strategic guidance, and keynote talks on responsible AI adoption.
Branislava Lovre
Branislava Lovre works with media organizations, CSOs, and institutions to implement ethical AI in practice, delivering hands-on training, strategic guidance, and keynote talks on responsible AI adoption.



Leave A Comment